TrueLarge-RT
Break the
Memory Wall.
Run 70B LLMs on 4GB RAM Android phones. We are democratizing AI by bringing massive models to the hardware the world actually uses.
Proof of Concept
Successfully ran Llama 3.3 70B on a 2018 Realme 2 Pro with only ~1400MB available RAM.
See the Impossible.
Watch TrueLarge-RT running a 70B parameter model on a 2018-era smartphone. No tricks, no remote servers—just pure native optimization.
The Problem: RAM-Bound Inference
Traditional Android inference engines are trapped behind the "Memory Wall." They require the entire model weight set to reside in system RAM to function.
The Constraint
A 70B model requires ~40GB of RAM even with quantization.
The Consequence
On 4GB/8GB devices, the app is instantly killed by the Low Memory Killer (LMK).
The Reality
Mobile RAM is expensive and fixed; mobile storage (UFS) is abundant and cheap.
A Native Powerhouse
TrueLarge-RT is architected for maximum efficiency on ARM-based systems. By bridging high-level Kotlin interfaces with custom C++ kernels, we bypass the overhead that plagues traditional runtimes.
- •Custom JNI Bridge for zero-latency control signals
- •Optimized LayerLoader using direct memory mapping
- •Deep integration with the Llama.cpp tensor engine
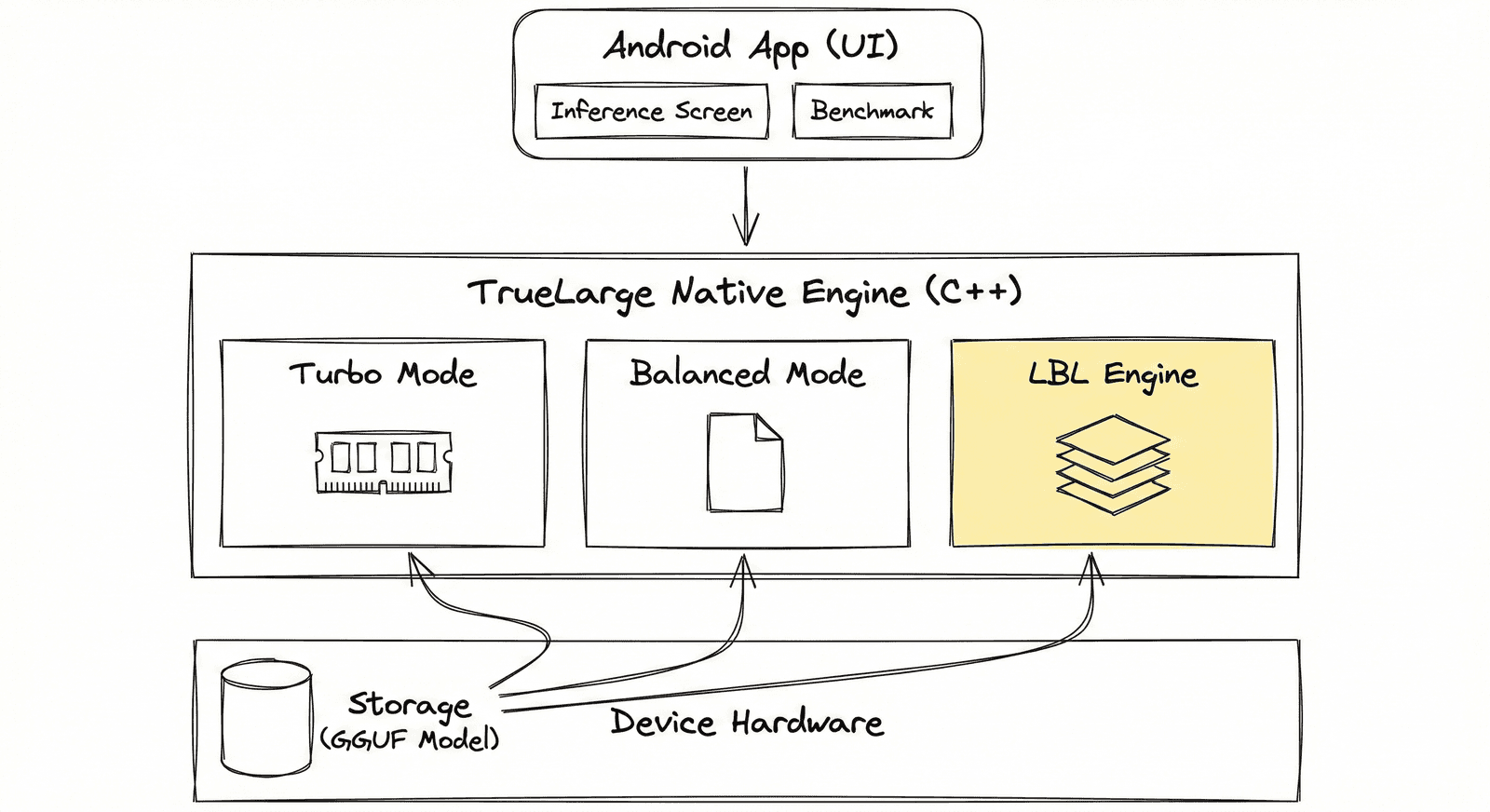
Smart Memory Selection
The engine automatically adapts to your hardware, selecting the optimal execution strategy based on available physical RAM.
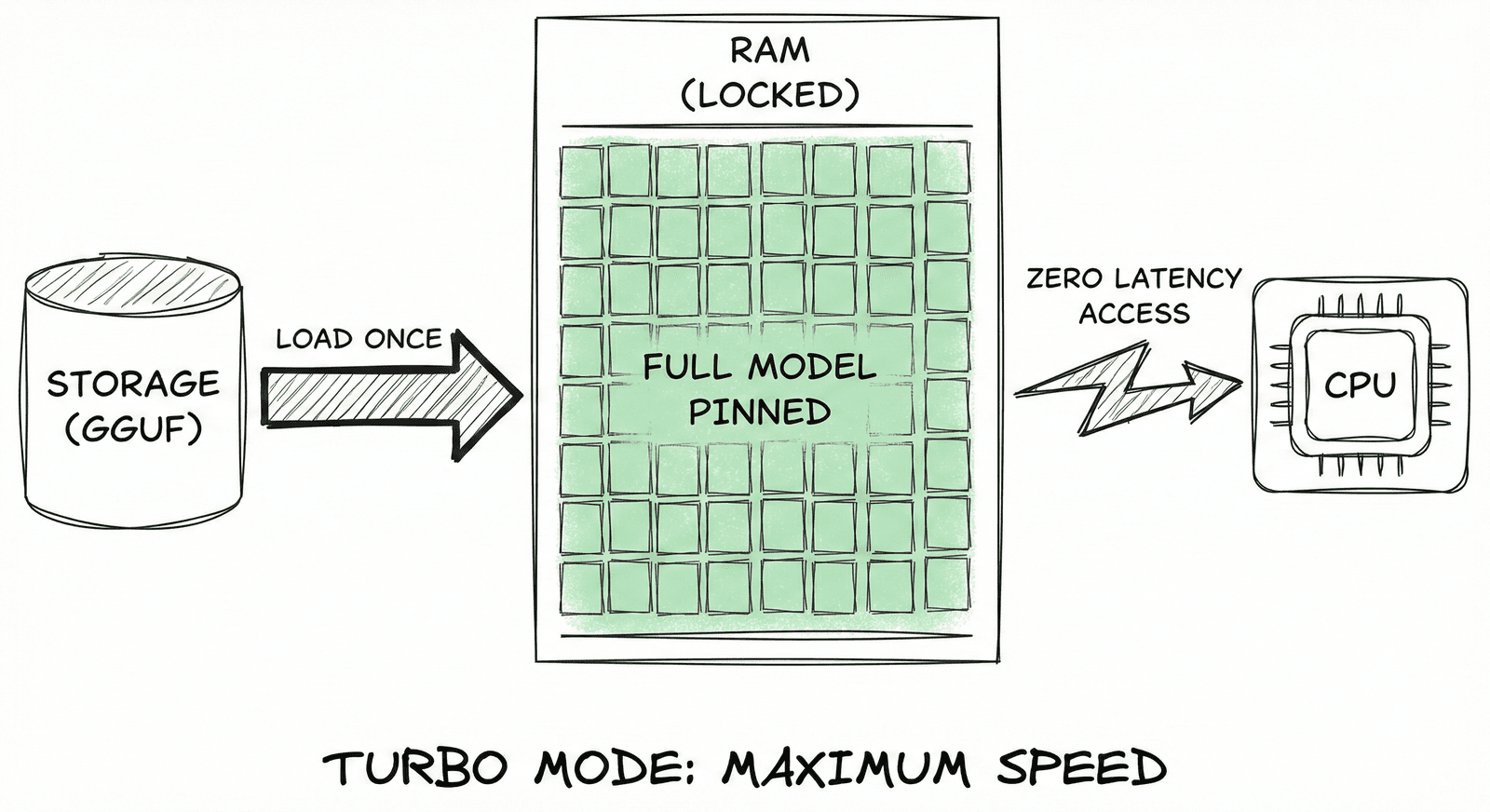
Turbo Mode
RAM-Lock (mlock) for flagship devices. Locks the entire model in RAM for maximum zero-latency speed.
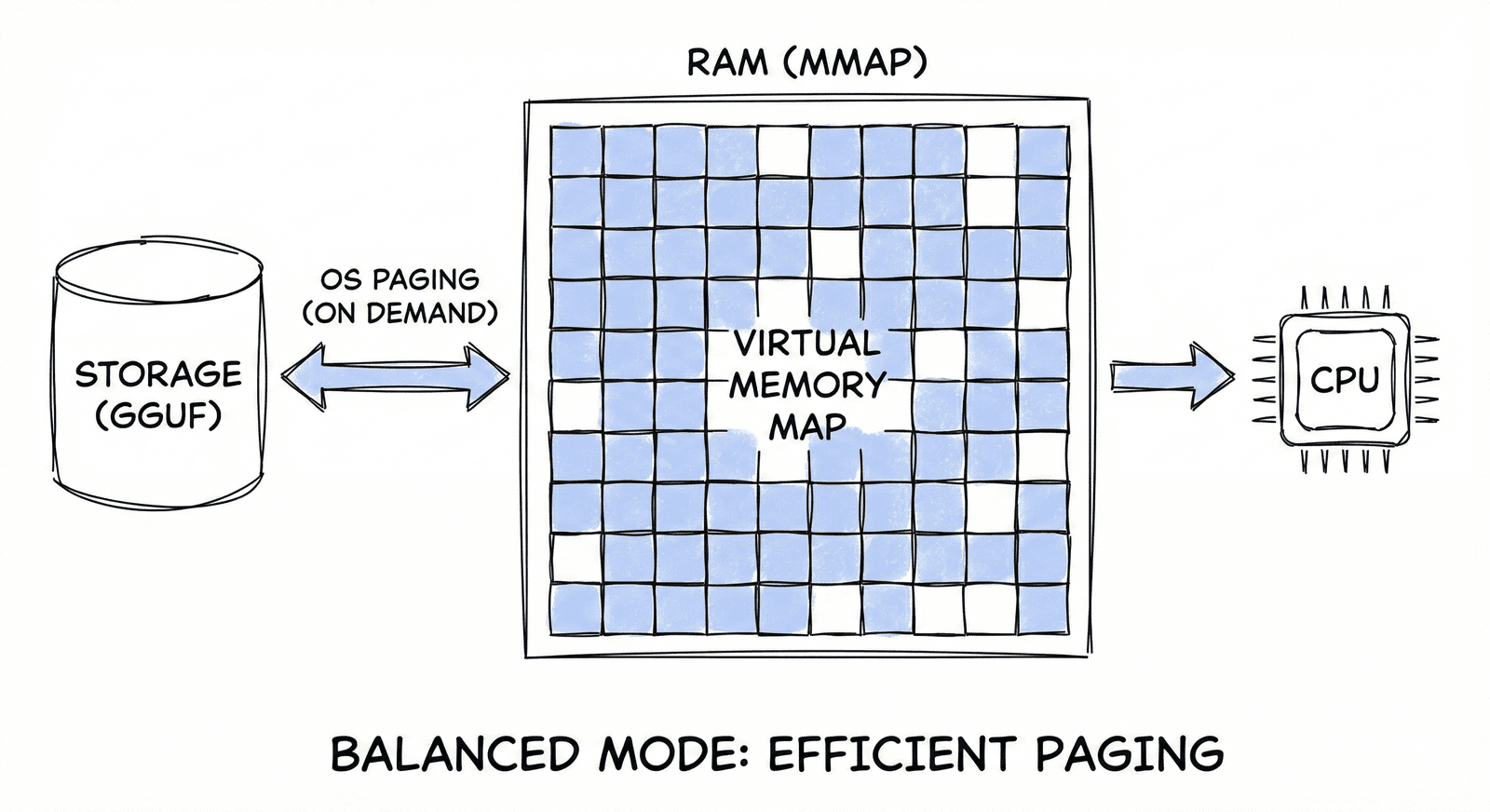
Balanced Mode
Managed mmap paging for mid-size models. Uses OS-level paging to intelligently swap layers.
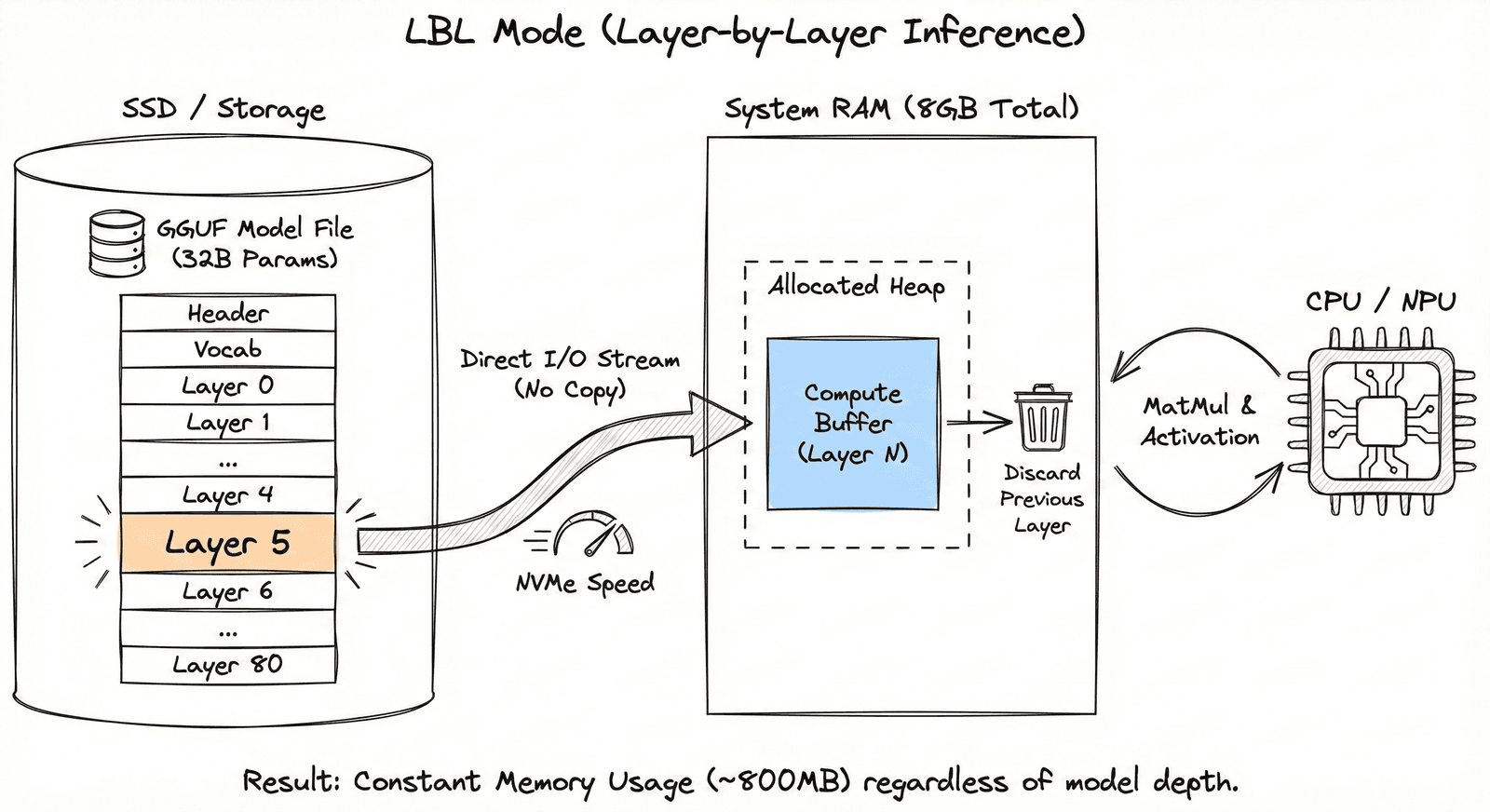
LBL Mode
Explicit weight streaming for 70B+ models. Ensures zero crashes even with < 1GB available RAM.
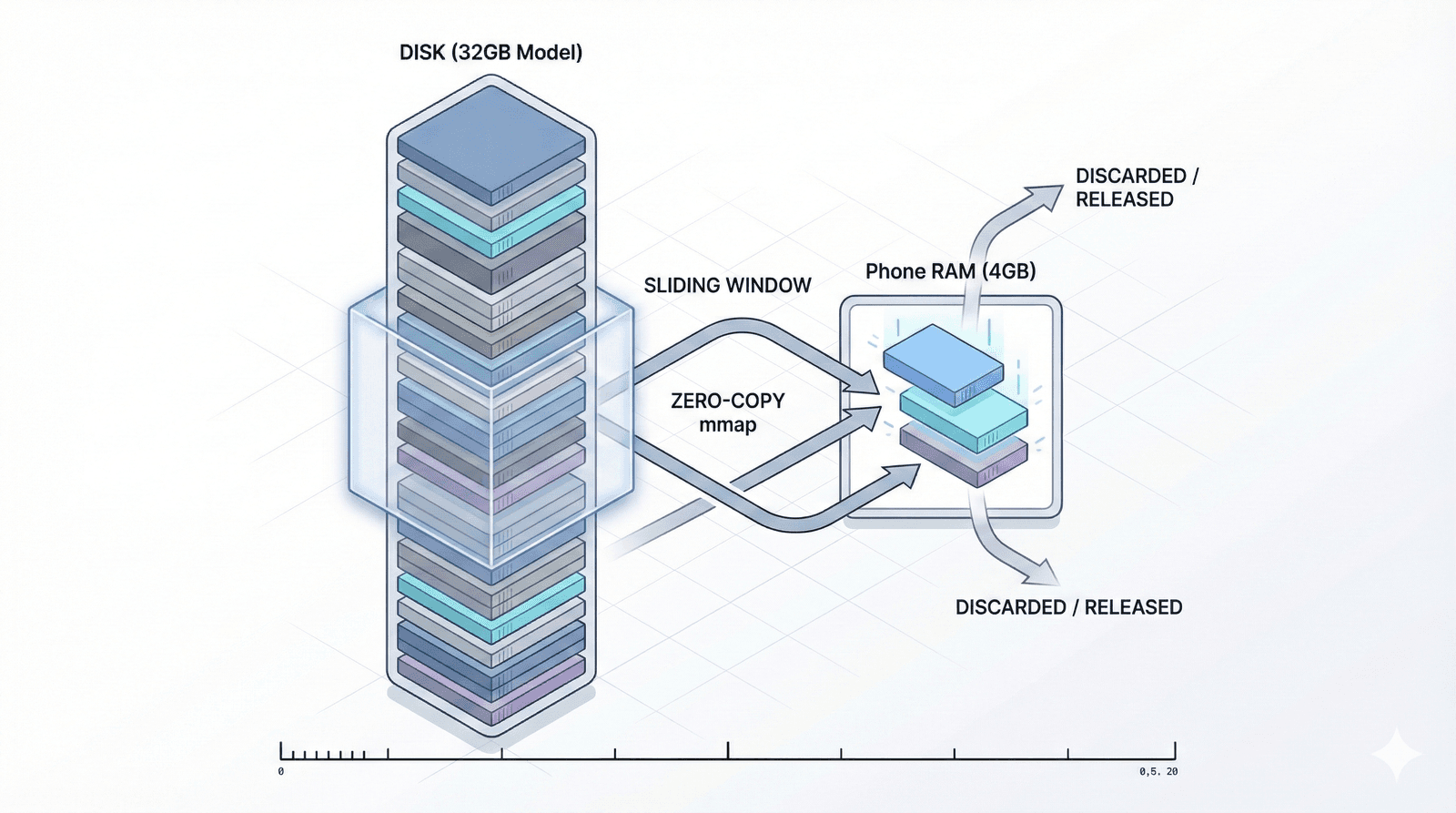
Deep-Pipelined LBL Engine
TrueLarge-RT treats RAM as a sliding window cache rather than a storage bin. It slices models into individual layers and streams them sequentially from storage.
LBL Mechanism
Models are sliced into layers and streamed sequentially, bypassing total RAM residency requirements.
Deep Pipelining
Eager prefetch queue looks 3-5 layers ahead. Layer N+1 loads while N computes, zeroing idle time.
Zero-Copy Mmap
Direct memory mapping talks to the Android kernel, avoiding expensive CPU copy cycles.
Key Features
Engineered for absolute stability and performance on the edge.
Smart Hybrid Engine
Autodetects device RAM and selects Turbo, Balanced, or LBL mode in real-time.
Ping-Pong Buffering
Two compute contexts swap roles—one computes while the other loads.
Precision Telemetry
4-digit TPS tracking and real-time hardware status (RAM, Disk I/O, Thermal).
Zero-Crash Stability
Sophisticated madvise hints prevent OOM by reclaiming memory proactively.
Infinite Scalability
Model size is limited only by your storage, not your physical RAM.
Native Core
Direct hardware access via Android NDK and custom-built C++ kernels.
Technical Stack
Core Engine
Native C++ (NDK) for direct hardware access.
Tensor Library
High-performance kernels from llama.cpp v3.x.
Memory Mgmt
Low-level system calls: mmap, madvise, mlock.
Concurrency
Multi-threaded scheduler with std::condition_variable.
Paradigm Shift
Standard runtimes are built for Servers where RAM is modular. Mobile phones have fixed RAM. We shifted the paradigm from RAM-centric to Storage-centric inference.
Research Benchmarks
Real-world performance on Consumer & Legacy hardware (SD660 / Dimensity 810). TrueLarge-RT prioritizes scaling on devices that otherwise couldn't load these parameters.
Throughput (Tokens/sec)
TTFT (Adaptive)
500ms+
Sub-second on RAM-Lock; context-aware.
Scaling Ratio
15:1
Model-to-RAM parameter density ratio.
Thermal Efficiency
-30%
Reduced throttling via kernel fusion.
LMK Stability
ZERO LMK
100% crash-free on background tasks.
OOM Resilience
ZERO OOM
Hard memory limits prevent system kills.
Control Latency
< 1ms
Zero-copy JNI signal transmission.
Hardware Verification Matrix
Validated on-device telemetry across flagship, mid-range, and legacy consumer hardware.
| Model Architecture | Device & Chipset | Storage Type | RAM Load | Speed (TPS) |
|---|---|---|---|---|
| Llama-3.3-70B (Q2_XS) | Realme GT Neo 3T (SD870) | UFS 3.1 | 1500MB | 0.040 |
| Llama-3.3-70B (Q2_XS) | Poco M4 Pro 5G (D810) | UFS 2.2 | 3000MB | 0.023 |
| Llama-3.3-70B (Q2_XS) | Realme 2 Pro (SD660) | UFS 2.1 | 1400MB | 0.010 |
| Llama-3.1-8B (Q4_K_M) | Poco M4 Pro 5G (D810) | UFS 2.2 | 3000MB | 0.100 |
| Llama-3.1-8B (Q4_K_M) | Realme 2 Pro (SD660) | UFS 2.1 | 1400MB | 0.045 |
| Qwen-2.5-0.5B (Q4_K_M) | Poco M4 Pro 5G (D810) | UFS 2.2 | 3000MB | 13.0 |
| Qwen-2.5-0.5B (Q4_K_M) | Realme 2 Pro (SD660) | UFS 2.1 | 1400MB | 15.0 |
Infinite Scaling Architecture
The Layer-by-Layer breakthrough means your RAM no longer dictates your model size. If you have the storage, you can run the model.
RAM_req = OS_Buffer + KV_Cache + Context_Window(1.2GB)| Device RAM | Max Model Capability | Execution Strategy | Performance |
|---|---|---|---|
| 4GB | 70B Parameters | Ultra-LBL (1 Layer Window) | 0.01 TPS (SD660) |
| 6GB | 70B Parameters | Streaming LBL (2-4 Layers) | 0.023 TPS (D810) |
| 12GB | 400B+ Models | Balanced Paging | High Throughput |
| 16GB+ | Any Compute-Bound GGUF | Turbo / Mlock | Maximum Native |
* Requirements based on 4-bit (Q4_K_M) quantization. Scaling is linear with storage throughput.
Research Findings: Why Dense?
"In an LBL environment, sequential weight access is the only path to zero-latency feeling."
Our research shows that Mixture-of-Experts (MoE) architectures, while efficient in compute, cause extreme storage-bound thrashing during Layer-by-Layer inference due to random router seeks.
Recommended: Dense Models
Llama 3 and Qwen 2.5 follow a strictly sequential flow. This allows the LBL engine to pre-fetch with near 100% disk utilization, hiding latency behind the compute of layer N-1.
Experimental: MoE Support
Sparse activation requires a larger 1GB context window and causes router-based disk stalls. We recommend dense 70B over sparse MoE for localized streaming.
2026 Roadmap
Inter-Token Pipelining
Eager Prefetch Queue
Multi-Layer Eviction
Micro-Pipelining
Why We Developed This?
"To bring intelligence to everyone, we had to shift the paradigm."
Standard runtimes are built for PCs and Servers where RAM is modular and expandable. Mobile smartphones are SoC-based (System on Chip) with fixed, expensive RAM.
In the developing world, 4GB and 8GB devices are the standard. By shifting from RAM-centric to Storage-centric inference, TrueLarge-RT makes the world's most powerful AI accessible to billions, regardless of their device tier.
Verified Architectures
TrueLarge-RT is engineered for the Unified GGUF standard. The following massive models have been verified on-device with zero LMK/OOM incidents.
Verified Architecture
Llama-3.3-70B-Instruct-IQ2_XS.gguf
Tested & Verified
Verified Architecture
llama-2-13b-chat.Q4_0.gguf
Tested & Verified
Verified Architecture
Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf
Tested & Verified
Verified Architecture
qwen2.5-3b-instruct-q4_0.gguf
Tested & Verified
Verified Architecture
Qwen3-8B-Q8_0.gguf
Tested & Verified
Verified Architecture
qwen2.5-0.5b-instruct-q4_0.gguf
Tested & Verified
 Join the Revolution.
Join the Revolution.
Experience production-ready LLMs on legacy mobile hardware.
For Android
Optimized for Snapdragon 8 Gen 2+ devices with 4GB-12GB RAM.
Mobile Download Note
Avoid opening in the GitHub App for a smoother download. If asked, choose "Chrome" or your "Browser". After download, find the file in your "Files" app.